Async iterators: a concurrency journey
After my initial attempt at playing with async generators, recently I decided to give a similar concept a go. This time, I had a task where I need to do a bunch of dependent requests to read a set of items from various backend endpoints to scrape them. Essentially, it is a paginated endpoint where I loop over to get the container ids and then I fetch the details for each child item as another list. Something like this:
Page(no) -> List of container ids
Container(id) -> List of itemsThis felt like a great use case for an async iterator that gives me the innermost items as I pull values from it. In reality, the item details were also fetched from yet another endpoint, but let’s leave this out for simplicity here. To build an example, let’s assume this is the initial paginated resource:
const wait = (amount) => new Promise((res) => setTimeout(res, amount));
// Resolves into an array of container ids in this page
const getPage = async (i) => {
await wait(1000);
return [1, 2, 3].map((inner) => `page ${i}, container ${inner}`);
};It returns 3 container ids for the queried page after waiting for a second. Then, I have this sub-request to get the details for each of these containers. It returns the item ids belonging to that container which takes another 500ms:
// Gets an array of item ids for this container
const getContainer = async (containerId) => {
await wait(500);
return ['a', 'b'].map((inner) => `${containerId}, item ${inner}`);
};Instead of crafting each and every operation on the iterators, I decided to go for a third party solution, in this case iter-tools, which is a very nice library impelementing basic composable building blocks. I nicely (and pretty naively) combined them like this:
// Calling this creates an async iterator that will yield the container ids from
// pages as final values b/c of the "flat" map.
const getContainerIds = (count = 3) => asyncFlatMap(getPage, range(0, count));
// Let's also measure the time
performance.mark('start');
await execPipe(
getContainerIds(),
asyncFlatMap(getContainer),
// Consume the final iterator to its full
asyncForEach(console.log)
);
performance.mark('total');
console.log('Completed in:', performance.measure('totalTime', 'start', 'total').duration);They compose beautifully, each result from the page iterator is mapped to the getContainer async function and it produces the final results for all of the innermost items, in order:
page 0, container 1, item a 0
page 0, container 1, item b 1
page 0, container 2, item a 2
...
page 2, container 2, item b 15
page 2, container 3, item a 16
page 2, container 3, item b 17
Completed in: 7595.9151999999995My problem was solved, I scraped my data. It took a lot of time though. While it was running in the background, my mind started wondering why? I attempted a naive fix with this magical asyncBuffer helper:
await execPipe(
getContainerIds(),
asyncFlatMap(getContainer),
asyncBuffer(10),
asyncForEach(console.log)
);Nothing has changed! quoting the docs:
For every value the next n values also start their computation in parallel. It may or may not be possible for useful work to be done in parallel depending on the nature of source.
Hmm, something started to click with me, just like my realization with async generators. Everything is sequential by definition. B cannot pull something from C until C has finished previous work and A cannot pull from B either. This will not magically solve my problem. Each time I pull a value from the final iterator A, it pulls one from the previous and unless they do something special, each iteration will await what’s before it. Next, I tried:
await execPipe(
getContainerIds(), // C
asyncBuffer(3), // ^B
asyncFlatMap(getContainer), // ^A
asyncForEach(console.log)
);And it was a relative success: Completed in: 5567.031. This is a little tricky to see at first, everything is still sequential. What happens is, when the first item is pulled from iterator A, it awaits a value from B’s .next. When B is first invoked though, it immediately calls .next() on C 3 times and keeps references to those promises. Whenever a new value is pulled, it will keep 3 items (one page) always scheduled for work. They will still resolve sequentially and will be available as the output of B.
When the first page request resolves, the first .next() of B, which was initiated by A also resolves and it triggers the first getContainer. Because a container id is consumed now, the second page load starts immediately to fill in its place. When first set of containers finishes fetching, and A ask for the next value from B, it already has the second page available and next getContainer can start. We have effectively overlaid the second page load with the container fetches dependent on the first page. The order of operations is much easier to see with a diagram;
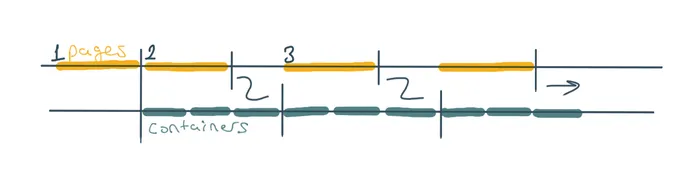
We still do all the container fetches sequentially and the first one should wait for the initial page request as it is dependent on it. The minimum time we can achieve with this scheme is getPage + page_count * max(getPage, 3*getContainer). In this case, it would be 1000 + 3 * 1500 = 5500, consistent with what we get plus some event loop and dispatch overhead. Increasing the number of buffered items doesn’t improve the total time for this example. That’s because each new set of items depends on its page request and we always fetch the items sequentially, in parallel to the page request that will block the next set of items. Similarly, the page fetches are sequential on their own so maximum number of concurrency we can get with this is 2.
We can theoretically fetch these in 2500ms assuming we could execute all requests in parallel - N page requests and M dependent container requests. To adapt this problem to iterators and improve the concurrency, the plan is parallelizing the container requests among themselves. Note that there is the probability that our page requests depend on the previous page in practice so there is not much reason to do page requests in parallel to each other. The sub-operations will be the bottleneck anyways.
await execPipe(
// We now have 9 pages of 3 containers -> 27 containers
getContainerIds(9), // F
// Fetch a page (3 containers) ahead of time
asyncBuffer(3), // ^E
// Create a sequence of sub-iterators for 9 container ids
asyncBatch(9), // ^D
// Create a regular array to cache it
asyncMap(arrayFromAsync), // ^C
// Pull a batch of ids from C and flat map it tru getContainer
asyncFlatMap((batch) => batch.map(getContainer)), // ^B
// Flatten to extract inner items
asyncFlatMap((i) => i), // ^A
asyncForEach(console.log)
);Here, the source iterator (F) is changed to produce 9 pages of 3 ids instead. Iterator E will try to eagerly pull from F to keep a total of 3 containers worth of page request active at a time. This corresponds to a single page in this setup. D on the other hand, will map 9 consecutive values from E into a sub-iterator. This is then converted to a regular array via C effectively caching the ids whenever 9 values are pulled from D. This is then mapped to an array of promises by B. As the final step, iterator A will flatten the items from getContainer and return them one by one.
This whole process takes ~9600ms which is equivalent to fetching 9 pages + the time it takes to fetch the latest 3 containers in parallel. Other containers are fetched alongside the previous page fetches just like our earlier example, thanks to asyncBuffer. The peak concurrency is now 4.
In practice, the pages may have different and varying number of containers in them and it can perform differently depending on the response time etc. On average though (even with a quirk that I don’t yet understand), the above iterator composition targets fetching 9 containers in parallel as soon as they are available and it is expected to take getPage * page_count + getContainer (assuming getPage > getContainer), which is pretty good. I don’t think there is a good way of representing a more complicated scheme like using the same pool of promises both for pages and containers using iterable building blocks though (or maybe there is, please let me know!).
In the end, I was quite happy how it turned out compared to pure Promise juggling. Even if you build a lot of helpers to do that, it doesn’t look as clean as this one and once you know how to tame iterators (I didn’t), this is pretty quick to come up with. You can turn something quite complicated into a chain of iterator helpers. The ability to call .next multiple times was the reasons why they have separated out a different proposal for async iterator helpers. There are still discussions around the concurrent behaviour and I am pretty sure I will not be the last person to get confused on the sequential behaviour of async iterators. You can reach me out for any comments or questions on Twitter.
Update: I later realized that getContainer mapper iterator could also accept the backpressure and initiate more than one fetch if the underlying implementation wasn’t based on async generators. With such improvements to the library, I just expect even the initial example above to work with some concurrency even though there is nothing we do later in the pipeline. Similarly, you shouldn’t need the manual parallelization that I did either.